
Using the backend API, I can get a valid response but it seems to be missing a few fields that the documentation says it would have. (Specifically, missing content and contentAsMarkdown)
Per RemNote
|found|Boolean|Was a matching Rem found?|
|_id|RemId|The Rem’s ID.|
|parent|RemId | Null|The Rem’s parent.|
|children|Array|The Rem’s children.|
|name|RichText|The Rem’s name.|
|nameAsMarkdown|String|The Rem’s name as markdown.|
|content|RichText | Undefined|The Rem’s content.|
|contentAsMarkdown|String | Undefined|The Rem’s content as markdown.|
|sources|Array|The Rem’s sources.|
|remType|Enum (string)|The Rem’s type.|
|isDocument|Boolean|Is this Rem marked as a document?|
|visibleRemOnDocument|Array|The descendant Rem that appear when this Rem is opened as a Document. (The order is arbitrary.)|
|updatedAt|Date|The date at which this Rem was last updated|
|createdAt|Date|The date at which this Rem was created|
|tags|Array|The Rem’s tags.(The order is arbitrary.)|
|tagChildren|Array|The Rem that are tagged with this Rem. (The order is arbitrary.).|
And here’s my json payload
Request returned 200 : ‘OK’
{’_id’: ‘redacted’,
‘children’: [‘redacted’],
‘createdAt’: 1644869250521,
‘found’: True,
‘isDocument’: True,
‘name’: [‘Software List’],
‘nameAsMarkdown’: ‘Software List’,
‘parent’: None,
‘remType’: ‘default_type’,
‘sources’: [],
‘tagChildren’: [],
‘tagParents’: [‘redacted’],
‘updatedAt’: 1644870773634,
‘visibleRemOnDocument’: [‘redacted’]}
This is missing the content field. Am I misunderstanding what the field should return? The Rem has text; I assumed contentAsMarkdown was essentially the same as hitting Share->Export->MD

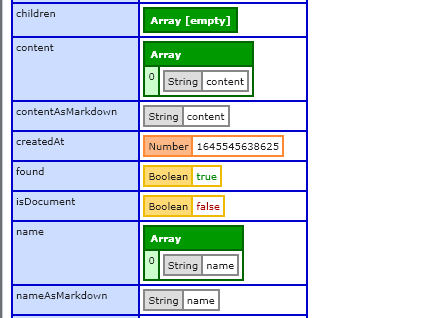
 .
. )
)