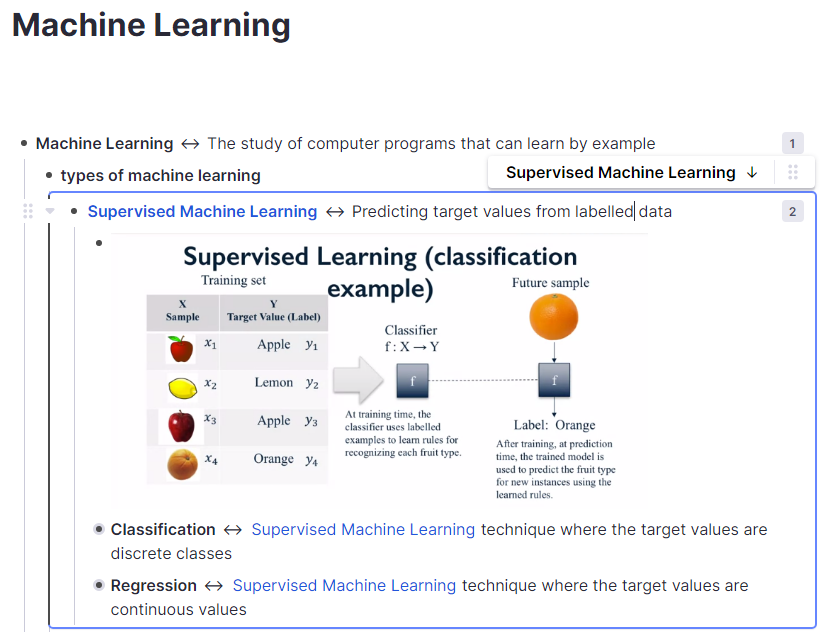
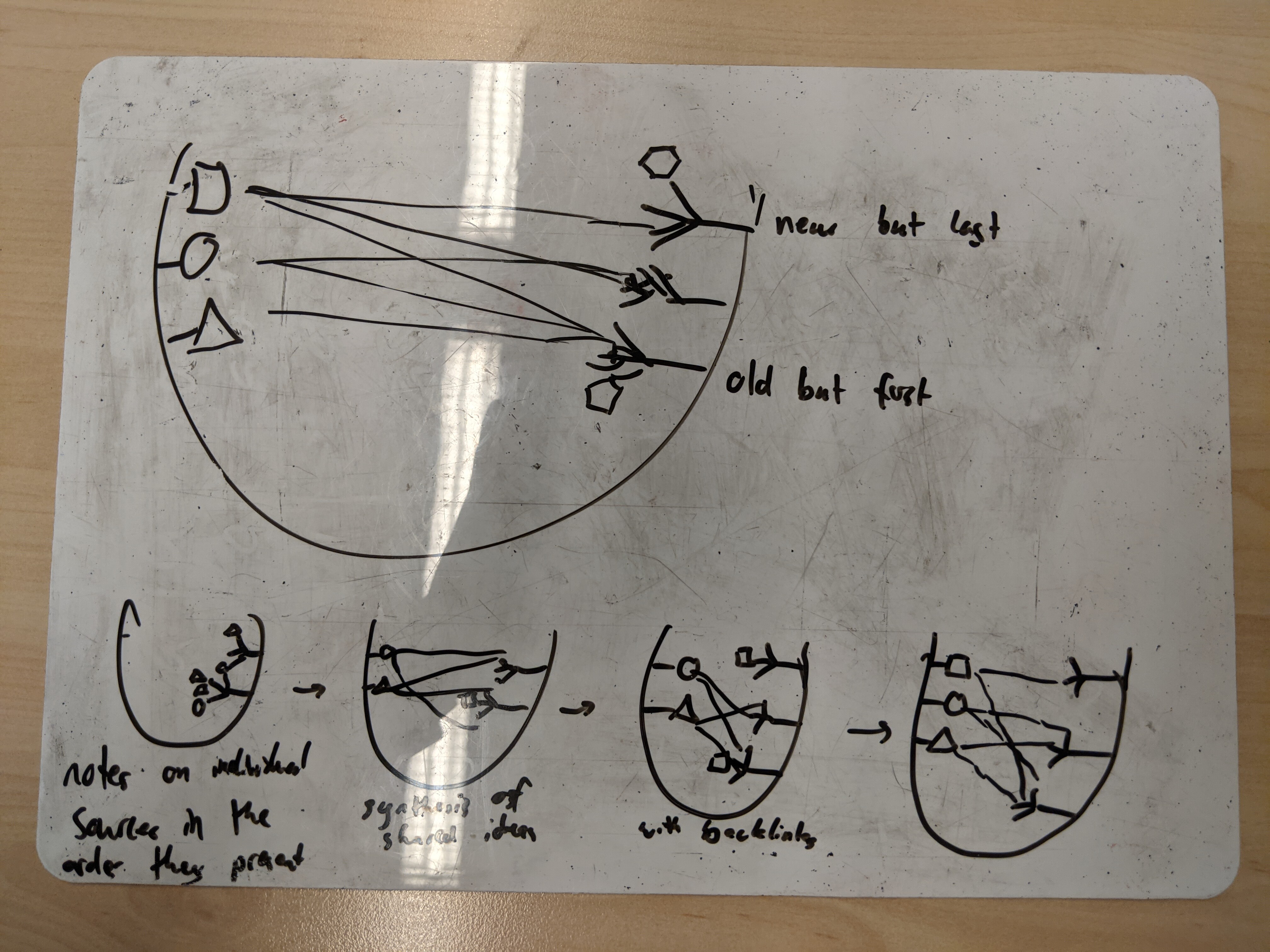
I like this. I drew a rough picture summarising what I got from it:
Take your master topic (e.g. ML) as one long rem. Bend that into a ‘U’. Summary index comes at the front at the top of the topic (on the left side with the shapes), original source-specific notes at the bottom (to the right the little trees).
Step 1:
Source-specific notes, structured in the same way those individual sources do it. These make atomic notes (marked as 
 ). Ideas that are unique per source stay with those source notes.
). Ideas that are unique per source stay with those source notes.
Step 2:
If an atomic note has SHARED material, it gets promoted to living in the index ( move from sources to index). Either you just more the concept rem (and leave the details behind). Or a portal to the details gets left where it started life in the original source (so that your original source notes aren’t disrupted), and you move the whole entry to the index.
Step 3:
As more sources get added, more concepts ( ) develop, and can get synthesised into the index. If something is awesome but not shared, you could arbitrarily promote it to the index even if it isn’t shared, but try to keep the index trim.
) develop, and can get synthesised into the index. If something is awesome but not shared, you could arbitrarily promote it to the index even if it isn’t shared, but try to keep the index trim.
The index can be structured in the way that makes the most sense to you. It doesn’t need to follow how the sources do things.
The two sorting rules I always try to follow are:
A. Like with Like. (Keep similar things in the same cupboard)
B. Place for everything. (I don’t have random unsorted orphan rem kicking around, at worst lone things get sorted under “Misc”).
My biggest takeaway from multiple rounds of trying to make good RemNotes: structure is emergent.
Just start, just try, it will be ugly and messy, but you can only refactor things once you can SEE those things and their details/patterns.
FIRST make things, THEN sort them.
Strict tree hiearchy is neat, but is also strictly linear. Often different topics have more than one ‘type’ of neighbor.
If you want to use branching trees, branch roots based on distinctions that you USE and that make sense to you intuitively.
As long as you know how to get there, it doesn’t strictly matter if your stuff is sorted perfectly logically.
In your example, make the definition of Decision Trees live under Classification and remember how to get there. Just add a little detail to Regression linking to Decision Trees reminding you that it can also apply there. (In file-folders you can leave an alias/shortcut to relevant folders which aren’t actually contained).