
Awesome, thanks for the link and the explation of the temporary solution! I really hope, they implement this feature soon! 
As a workaround you might use the  Active Recall Custom CSS (What is Custom CSS and how do I use it?).
Active Recall Custom CSS (What is Custom CSS and how do I use it?).

You can try to remember stuff directly in your document and optionally after you finished practicing use the “Practice all cards in the Document” thing and just click Solid everywhere to record the practice session.
6 Likes
Congrats for you thorough explanation. But I disagree with your desire of reviewing all the descriptor of a concept together. This idea goes against the principles o Spaced Repetition.
Going back to Piotr Wozniak (creator of SuperMemo in the 1980s) https://www.supermemo.com/pt-br/archives1990-2015/articles/20rules, you must stick to the minimum information principle. Each “slot” of information must have its own schedule. Otherwise, if you forgot 1 of 6 descriptors, will you have to drastically reduce the intervals of all of the 6 descriptors? That would not make sense.
Using Anki for a long time, I can assure you its even good to see these things separately. You will always be reactivating those related synapsis. And to have I full picture of the subjetc, RemNote has the great advantage that you can anytime open a new window and search for the original document (here is a drawback of RemNote - not having a button on the queue to directly opening the document in the rem that is being asked in the card, forcing us to open a new window and make a search).
But you can believe spaced repetition. It does not go against seing the big picture. Instead, it warns you when you should do this. When making a flashcard of one descriptor you fell you are not sure of the answer of another descriptor, you MUST solve this uncertainty immediately. Recalling randomically, with less context being supplied, is the key for enforcing your memory and truly mastering the content.
I prefer to think of RemNote as I very good tool to apply SR without losing the big picture. But messing the spaced repetition in not an option, at least as I can see.
1 Like
The recommended implementation (through Powerup) is not going to change any default behavior. It is going to be an additional feature that gives user the flexibility to decide at what level of granularity the randomization should happen. So it is essentially ‘if you don’t like, don’t use it’ feature.
Having said that, here are my thoughts on some of the points you mentioned.
The essence of minimum information principle is to create prompts
- that are simple, precise and consistent
- that you should be able to answer correctly almost all the time
- that should light the same bulbs every time you review them
The easiest way to violate minimum information principle is by creating a prompt has more than one thing in it. However, in a rem cluster, we are reviewing only one prompt at a time. As long as the prompts inside a cluster do not violate minimum information principle there is no issue here. A cluster just means that the learner wants to think at a slightly higher level of abstraction. Only one issue here is the cost of forgetting a cluster. This cost is not same as cost of forgetting a complex item that Piotr talks about. It is because members in a cluster are not complex to begin with and members have their own schedule. I will explain in detail towards the end.
Also, let’s not confuse Spaced Repetition with flash cards. The benefit of SRS comes from spacing and repetition. You can apply SRS at any level. One popular example is Ali Abdaal’s Retrospective Revision Timetable in which he applied SRS at chapter level. Flashcards implement SRS. e.g. Anki is a software that implements SRS at flashcard level, but RemNote is way more than just a flashcard software. In its true essence SRS only deals with scheduling (i.e. intervals) of the units of knowledge it is dealing with. The size of the fundamental unit is up to the learner. It can be a flashcard or a small cluster or something even bigger. I even say that SRS applied at flashcard level (and the typical Anki style flashcard reviews) is prevalent because initial tools like Anki and SuperMemo popularized that idea. Even RemNote borrowed that idea and innovated it by adding hierarchical context to the cards (which is great). But ultimately it is similar to how people kept innovating Internal Combustion engines for centuries. RemNote can do more than just imitating Anki. With outliner capability, the new graph feature and all other great features, RemNote can change the way we learn.
I have suggested a solution for this at the bottom of the request, under What if I forget one card from a cluster?. The funny thing is, the idea of a cluster already exists in some sense, even in Anki, it is called a List. A list schedules a small group prompts together and in sequential order. So the worst case penalty is same as forgetting a list. But we can come up with better algorithms to deal with this. One such case I mentioned is, if I forget a member from the cluster, that member is considered forgotten and gets kicked out (temporarily) of the cluster. Now to schedule reviews for this forgotten card, we can take into account the next repetition interval of the cluster and plan the relearning phase of this forgotten card in such a way that one of the forgotten card’s reviews aligns with the next review of the cluster. So when the user reviews the cluster next time, the forgotten card will also become part of the cluster review. If the forgotten card gets answered correctly, then from that point onwards we can schedule the forgotten card along with the cluster. So the cluster idea gives the user a chance to test if the forgotten card can actually get back to its original schedule, thereby actually reducing the number of future reviews of the forgotten card. This idea can be applied even to lists to actually reduce the penalty of forgetting lists, especially when we forget just one or two members of the list. This is just rough idea, there can be corner cases to this and this will make scheduling complicated from the tool implementation standpoint.
While I agree with the fact that random recall will put more intellectual load on the memory and potentially result is better enforcement, only downside is the practical aspect of it. For example, if I am seeing a card after 6 months, it will be hard to just sit there and think about all its sibling cards. All I want to do at that point is to answer the card, complete the review and get on with life.
The bottom line is, everyone learns differently. Above all, this is just an optional feature.
5 Likes
Am I just unlucky or are clusters already a thing? For example I get the descriptors of a parent in groups and all the clozes as well. I even turned off all cluster settings yet I still experience this issue
As you probably know, there has always been some level of ordering by default. I think the ordering depends on how many cards are there in the queue, what are the card types, in what learning phase those cards are in and also what is the state of Cluster settings (these are just my observations). If you have just descriptors and those cards are new, there is a good chance that you will get them in sequential order
Actually, we also need some improvements to prevent sequential ordering where it doesn’t make sense. For example this feature - Bury related new card until next day from last June (from Discord) and Bury (automatically) other cloze cards on the same rem
Accidentally found this amazing feature! Thank you!
1 Like
Do you think you can connects this to SM2 Algorithm? Or maybe simple ones like adding a reminder of one day, one week or one month automatically after review?
Or maybe a button. After reviewing the note, showing a button so there won’t be any need to ##learned.
Not really. And it would also defy the intention of spaced repetition, e.g. read this excellent post by liberated_potato.
Don’t think this is possible either because we can not store that information easily.
If you are struggling with a this you can always tag a rem with a !!nextweek or something.
You can also copy the learned rem as tag (Ctrl + Alt + S) and just paste instead of typing to speed up the process.
2 Likes
Hello, guys! I’ve been using Remnote for about 3 months now, and one thing that would improve my experience with the app, and hopefully others too, would be the option to practice the flashcards in the descending order that they appear on the documents. That would allow us to create a solid line of thought and get a better grasp at the topics in an organized manner, especially if it’s the first time we are visiting that subject.
Have you tried Rem Clusters?
Try Settings > Queue > Ordering.
Also see Rem Cluster - a group of rems that can be reviewed together in sequential order.
Yes, I’ve tried using rem clusters, but it doesn’t seem to work properly, since I still see a lot of randomness on my queue. And thanks, I already upvoted that feature request.
You could also use this css to practice flashcards in order: RemNote Library
and an explanation remnote-library/README.md at master · hannesfrank/remnote-library · GitHub
I personally wouldn‘t really recommend doing flashcards in order though or at least not every time. Sure it‘s much easier and faster but as research shows you remember things the longest when you struggled recalling that information and randomness is one way to make it more difficult for yourself. Ordered flashcards also get predictable in my experience. Before a recent update where you mostly encountered flashcards in order, it often happened to me that I was able to predict the answer to a card because of the last card I saw, which I found pretty annoying.
I am newbie. Can you give more detail on how to do this? Tks.
1 Like
It will be helpful, i really need this function
2021-07-18T18:30:00Z
Hi,
Remnote team,
I Prepare hierarchical Questionnaire like Mentioned below.

So 6 individual Questions => Reduced to 1 hierarchical question, then i use multi rem card for reviewing, but unable to see the child rems while reviewing Rems in Queue
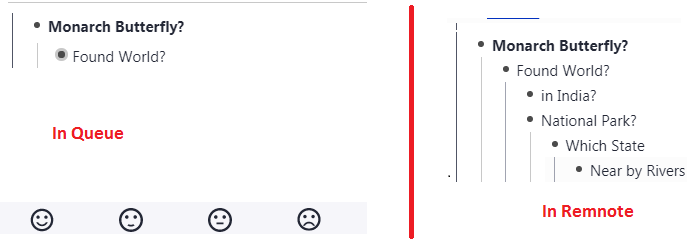
Unable to expand below rems in queue except by peeking it into document which is inefficient all the time.
Any way around
- to See all child rems in queue itself,
Current Method used: Make all child rems as multi rem queue and disabling it, until reaching Parent Rem from child rems
So the feature request be like : Multi Level List /Line Queue => To make child rems also as Multi Level list/line queue.
Thank you
2 Likes
If any one thinksTopic name doesn’t match with its description pls do changes in topic name
This is what I was going to suggest. I think our brain doesn’t only behave like 1rem question to answer but 2 to 1, 5 to 3 sort of things. This is a good point! 
Of course, You can make those questions to 1rem question. but the way is very time consuming and requires burdensome work and even not perfect.
It has many advantages
-
It Reduces the no of questions in queue, and Giving all the contextual questions to be revised at once , they serve as a clue to next question.
 (Connecting Ideas)
(Connecting Ideas) -
If any full article is important, the only way to review the article in whole is by making questions(which is meaning less, ROI is Poor) or Peek ACD, as still no reminder(Reminder with Spaced Repetition= Awesome feature) option is available yet in remnote.
So as a Learner there are some information to be
- Digested or Internalised (Where Return on Investment (ROI) is very High => like probable questions in Exam) => Making Individual question Rems
- Only to be Reviewed (ROI is Less, Not so probable questions in Exam, but it needs to be reviewed)
hope this  will resonate with others as well.
will resonate with others as well.
This feature will serve both as a reminder for whole connected Parent and Child rems.
The sole reason for coming to Remnote is : Notes with Spaced Repetition (for Individual Rem  but for Whole Article(Parent and child rem :
but for Whole Article(Parent and child rem :  )
)
Reminder with Spaced Repetition= will be Awesome feature to give option for the user to choose like
- Review at Specific date
- Review at periodic intervals (Spaced Repetition)
Thank You
2 Likes