
I’m sure full regexp would be great, but for now even the addition of AND and NOT could make every search portal from a waste of space to a meaningful part of RemNote. Off the top of my head, you could make a few portals for various todos based on granular tag criteria (short term, long term, urgent, non-urgent, family, school, work, etc.), organise your apps list in one place and bring in specific sections to various projects (either by ANDing those sections or NOTting the extraneous ones), filter rem based on existing powerup tags (e.g. only red AND h1 so you could create a queue to practice subjects you have marked as difficult rather than manually portalling them one by one).
2 Likes
This is probably included in your suggestions, but I’d like to make it more explicit. It seems important to me that one can nest these network relation things. So, for example, one could ask “find all rems tagged as #important that are children of any document that is tagged with #Work. Oh, but not the ones that are hidden in those documents. Ok, now show me those, together with their children (but not the children tagged with #comment)”
1 Like
Thanks @UMNiK, @helado. I added regexp, highlight (I like the convention of using colors to mark difficulty) and hiding state to search and show children/parents to output modifiers.
Since each rem can have a different hiding state when opened in each of its ancestors in the hierarchy we must be explicit about the context there somehow.
Summarizing this discussion on Discord: https://discord.com/channels/689979930804617224/719288461231652984/791200050994741248
Path Queries are strictly more expressive than just boolean operators and they have real use cases.
- Similar to SPARQL Property Paths which uses
/syntax plus multiplicity operators similar to regex (+, *, ?).- Example:
?item wdt:P31/wdt:P279* ?class.
- Example:
-
>would also be intuitive because it reminds of breadcrumbs-
A > Bselects direct children of A -
A >+ Bselects descendants of A -
A >? Bselects A and children of A -
A >* Bselects A and descendants of A
-
- I used the convention to return the rightmost part of the query as result
- Syntax example (returning all unfinished, important, not hidden and not commented todos in all documents/rem tagged #Work):
#Work >+ (#Todo.unfinished AND #important AND !%hidden AND !#comment)
- To return ancestors/parents instead of descendants/children one could mirror the symbol:
A < Breturns the parents of a set of rem A
What is the result?
- Here the rightmost term is supposed to be the returned result.
- This is sometimes inconvenient e.g. if you want to find an ancestor satisfying multiple conditions:
[[A]] <* _ AND [[B]] <* _ AND _ <* #Document(documents containing both [[A]] and [[B]] somewhere) Here a temporary variable would have to be added somehow. - SPARQL and SQL use a
SELECTclause to name the result explicitly which is a bit inconvenient for causual queries. Or can we make a nice convention for this since the result will be usually just a set of rem? - The returned set of rem should be displayed in a (Search Portal). If there are subtrees in the results this particular subset could be aggregated and displayed together. Ancestors are hidden and displayed as breadcrumb list as usual.
Hiding adds quite a bit complexity. Maybe consider FR Make folding be different from hiding first.
- Hiding state depends on the opened rem. There are a few strategies how to handle this.
- Favorite: Always consider the state it has in the ancestor #Document or top-level (#Stub) rem.
- The state it has in the previous node in path queries.
- There could be a checkbox option on the search result box (or a global search modifier) to show or hide hidden rem.
- Path Queries from parent to children can be pruned when a hidden rem is encountered.
- A hidden parent and visible child can only occur in portals which we have not considered yet. One strategy is to treat portaled rem as transparently included into another place in the hierarchy meaning that they don’t have more parents besides the one at their original place in the hierarchy.
Logical Operator Scope
-
In RoamI misinterpreted this, see below. Logical operators in Roam consider a branch in the hierarchy tree, not individual blocks or pages as a whole. Assuming it would work like previously described:[[A]] and [[B]]returns all blocks containing either reference when the containing page contains both references anywhere- This could be expressed more explicitly as
[[A]] >* [[B]] OR [[B]] >+ [[A]] - Maybe consider a shorthand
[[A]] ~ [[B]]or do we want max compatibility with Roam? - I find it more intuitive if
ANDonly returns rem having both references/satisfying both conditions.
- This could be expressed more explicitly as
3 Likes
This whole thread is on another level 
I probably want all of that too, I just don’t know it yet 
Only things I could add, I already described here:
Everything I mention there seems to already be covered here, except perhaps the option to give a “name” or “title” to a search, making the design cleaner by hiding the possibly complex formulas.
A friendly UI for the actual search would definitely be a must, since most users wouldn’t want (or be able) to type long queries (especially the more complex ones; typos are bound to happen).
3 Likes
I think you got it wrong about how Roam handles it with logical operators .
When you do a AND search for A and B :
- It looks for blocks that have both in it
- It looks for blocks that have either A or B in it , while having the other one in one of its direct children .
- The example that you quoted assumes that any block under a page is it’s child , and also that it returns the pages that contain A and B anywhere within it . That’s not true and would be a completely useless result IMO .
- use case wise , when you do a AND search you are just searching for cases where you have written about both A and B together . It could be in the same line or directly indented beneath it . That’s when you write something together right ?
If you make a sibling (not a child) then they aren’t things that you associated strongly together so wouldn’t fall under AND .
Oohhh , this is getting so interesting.
I will explain with screenshots if you didn’t get how Roam does it . I don’t want to duplicate what roam does , but I think using it as a working model we can learn a lot from what it handles right and misses .
I am bit caught up with the Aliasing project right now , but I definitely want to return to this and work long on solving this one ! Thanks for starting all this ! You were a budding remnote user when I stopped frequenting the channels , now you have taken over  good for you !
good for you !
2 Likes
Oh, mb I get it now. AND is satisfied in Roam when the path/branch in the hierarchy tree contains both references which makes totally intuitive sense when dealing with an outline editor where indenting is key to express relations between ideas.
Maybe it’s actually a good idea to copy that or at least have the option to do this by easily. Ctrl + q search works the same after all.
1 Like
Oh wow , I didn’t know the normal search box worked that way in remnote .
I am glad you understood, I should really work on my explanation skills 
1 Like
On the topic of queries and aliases together, this piece comes to mind https://www.roambrain.com/in-search-of-the-literature-x-ray/ . Even more blue sky than meaningfully querying parents and children in an infinite outliner.
1 Like
user case:
show projects that has deadline date in 3 days from today.
query:
/work/*[#project][@priority=1][!!today - @deadline < 3]
Here I’m drawing syntax from XPath.
@ is the value of attribute.
If there’s support for value of tag or descriptor, the query will be more powerful.
3 Likes
I’d like to have a compact way to express complex filters like: "show me all rems that are tagged by X, or have a reference to X, or have a descriptor who has reference X ".
use case: Say I have the rem “Physics”. I may tag some related documents with #Physics. But if the title of a related document contains the word, like “[[Physics]] of plum jelly”, I tend not to tag. Then another document may be about a #Book, a tag which adds descriptor slots author and subject, and in the latter I put [[Physics]] in the back of the card (or as a child). In these cases, I’d like a simple way to find them all in the same query.
1 Like
today I encounter another case:
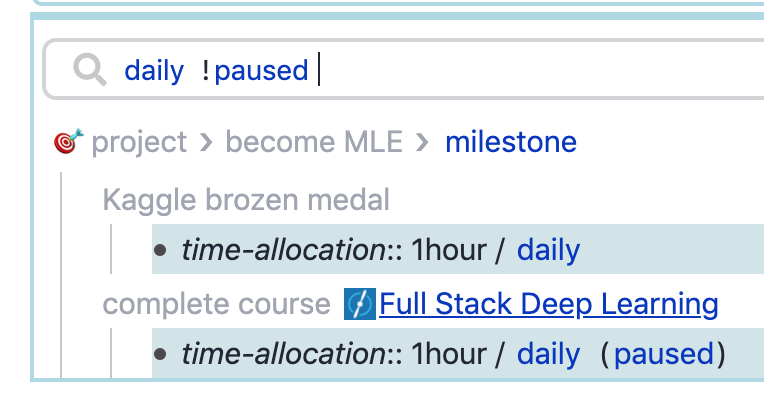
I have many projects classified with tag. Some projects are paused.
I need for daily projects except the paused ones.
query: [[daily]] ![[paused]]
so it just is a basic boolean logical for negation !.
rant:
Remnote should add basic boolean logical for search first and advanced latter, that is big leverage for information reformation into views so as to make same info useful for different context.
Their focus on graph somehow is not useful to me.
4 Likes
Agree. Boolean search is such an essential thing. (which is also why I don’t think it makes sense to paywall it)
1 Like
Maybe I missed it. It seems important to be able to filter by dates of creation and last-modified. When you know you’ve added something but it’s getting hard to find, you almost always have a sense of when you wrote it, and this will be more obvious as we use remnote for longer.
1 Like
- inline content: latex, bold, italics, highlight, cloze, link
Remnote does a great job of searching any phrase. But then i can select only 1 item from the search results. And to see other results i need to search again. Is it possible to show search results on a separate page. It would be like creating tags on demand and seeing them on a dedicated page.
1 Like
Try using a Search Portal. I think this is exactly their use case.
They feel a bit buggy for me, especially when searching for multiple words.
I’d also like to be able to see all search results in the search popup. Maybe have an option for the number of default shown results and an extra command (e.g. alt + enter) to show more/all results.
1 Like
What you are describing are queries (see them implemented in Roam), they are on the roadmap.
thank you!!
any idea about the ETA?
None whatsoever. Keep checking the update notes as they come in, I suppose.